








Benefits
Drive more efficiency, create better outcomes and make more informed decisions with modern content management solutions.
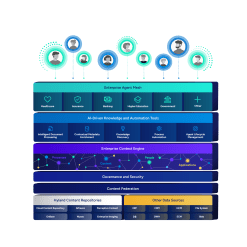
Organize and optimize all content and assets across the entire organization.

Content and data are growing in volume, variety and velocity, but legacy systems weren’t designed to manage it in a way that meets the demands and requirements of modern organizations. Hyland simplifies how users interact with the information they need by making it easily findable and accessible while keeping it secure and compliant.
Hyland’s content management features:
Support internal and remote users, as well as external stakeholders, with always-available access to the information they need.
Simplify content management and collaboration with features like version control, electronic signatures, annotations and audit trails.
Establish a single source of truth and eliminate content silos throughout the enterprise without complex and expensive legacy system migrations.
Search across all federated repositories to find the relevant information wherever it is stored.
Work digitally regardless of document format, and support high-resolution, rich media photography and videos, complex CAD drawings and more.
Enable users to easily, securely and quickly view content regardless of file size or format and without requiring native applications.
— Mauro Cacciafani, Architecture & Security Manager, Publiacqua S.p.A.


Meet industry-specific needs for managing content.
Manage your particular content
